A $500 GPU Just Outscored Claude on a Coding Benchmark. Here's Why That Matters for Your AI Strategy.
ATLAS shows how orchestration around a frozen 14B model can compete with frontier coding models, changing the enterprise AI cost equation.

A single developer, working with a frozen open-source model and a consumer-grade GPU, built a system that outscored Claude 4.5 Sonnet on LiveCodeBench. No fine-tuning. No training. No cloud API calls. The model itself didn't get smarter. The system around it did.
If you're calculating your enterprise AI ROI based exclusively on frontier model capabilities, this project should make you reconsider what you're actually measuring.

The Headline, and the Asterisks It Deserves
The project is called ATLAS (Adaptive Test-time Learning and Autonomous Specialization). Running a frozen Qwen3 14B model on an RTX 5060 Ti, it scored 74.6% on LiveCodeBench, compared to 71.4% for Claude 4.5 Sonnet and 65.5% for Claude 4 Sonnet.
Before you run with that comparison, the context matters. This is not a controlled head-to-head. ATLAS was evaluated on 599 LiveCodeBench tasks using a multi-candidate pipeline. The Claude scores come from Artificial Analysis, which tested on a different subset of 315 problems using single-shot generation at temperature zero. Different task sets, different methodologies, different conditions.
ATLAS also trades speed for accuracy. The full pipeline can take minutes per task where a single API call to Claude returns in seconds. And the benchmark is coding-specific. ATLAS was purpose-built and tuned for LiveCodeBench; its scores on other benchmarks like GPQA Diamond (47.0%) and SciCode (14.7%) are considerably lower and haven't been optimized.
I'm leading with these caveats deliberately. The point of ATLAS isn't that a $500 GPU "beat" a frontier model in some absolute sense. The point is what it reveals about where performance actually comes from, and that has direct implications for how enterprises should be thinking about AI investment.
The Model Didn't Get Smarter. The System Did.
ATLAS took a Qwen3 14B model, a mid-tier open-source model that scores around 55% on LiveCodeBench when used conventionally, and boosted it to 74.6%. That's a nearly 20-percentage-point improvement without changing a single model weight.
How? By treating the model as a component in an engineering pipeline rather than an oracle you query once and hope for the best.

The system operates in three phases, and they mirror what any experienced software engineer does instinctively when tackling a hard problem.
Phase 1: Generate. Instead of producing a single answer, ATLAS extracts constraints from the problem and generates multiple diverse solution paths. It uses a technique called PlanSearch to explore different algorithmic approaches, combined with budget forcing to control how much compute each candidate receives. This phase alone accounts for 12.4 percentage points of improvement, taking the baseline from 54.9% to 67.3%.
Phase 2: Verify. The system scores and ranks candidates using a combination of energy-based scoring on the model's own internal embeddings and sandboxed code execution. Interestingly, the developer is transparent that this phase contributed 0.0 percentage points in the current version. The scoring mechanism was trained on too small a dataset to be effective. It's a component that exists architecturally but hasn't delivered yet.
Phase 3: Repair. This is where things get genuinely clever. When all candidates fail, ATLAS doesn't just give up or regenerate from scratch. It creates its own test cases, uses chain-of-thought reasoning to diagnose why the code failed, and iteratively fixes the solution before submitting. This self-repair loop rescued 42 out of 194 failed tasks, adding another 7.3 percentage points.
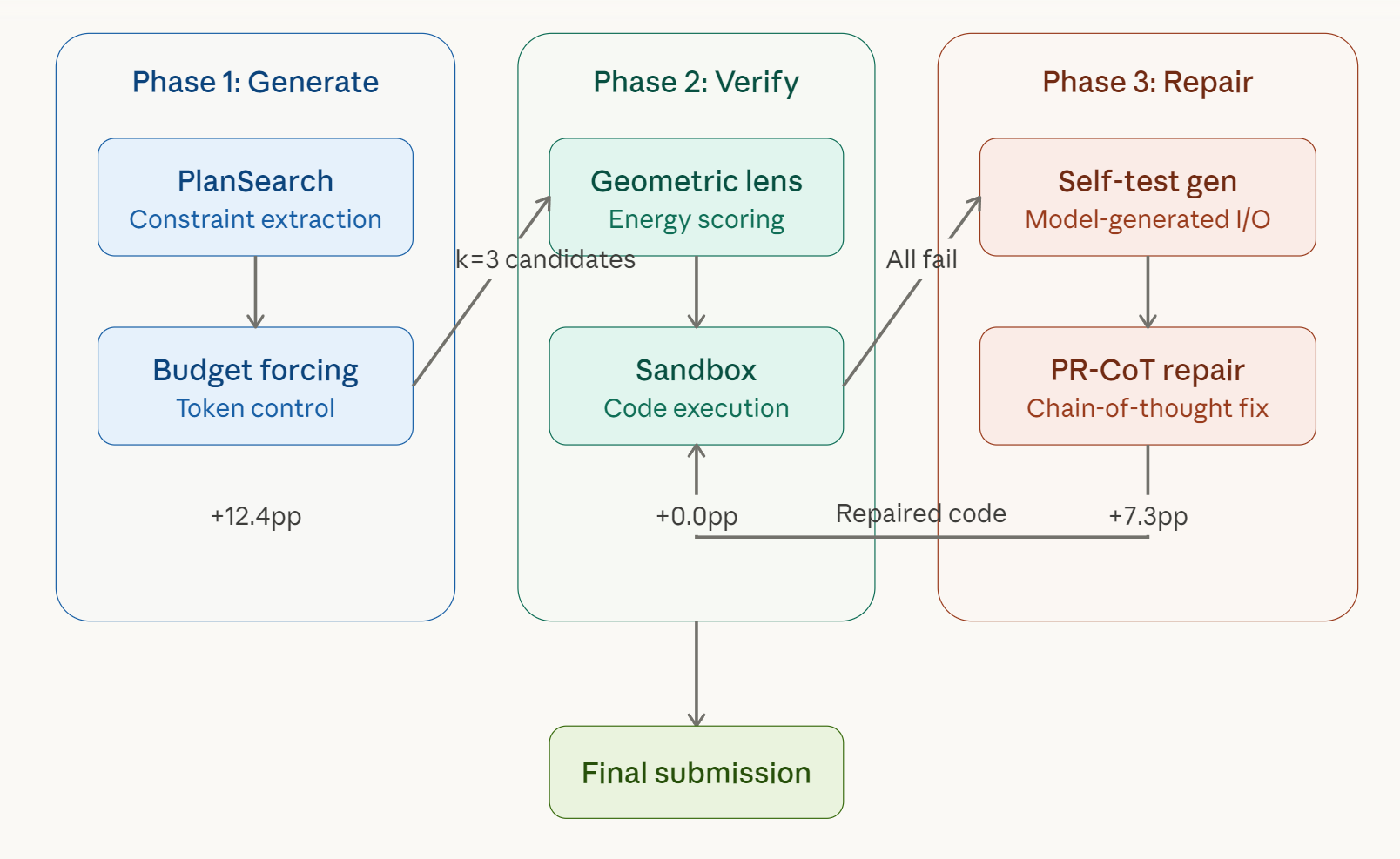
The full ablation breakdown tells the story clearly:
| Phase | Configuration | Pass Rate | Improvement |
|---|---|---|---|
| Baseline | No V3 pipeline | 54.9% | — |
| +Phase 1 | PlanSearch + diverse sampling | 67.3% | +12.4pp |
| +Phase 2 | Lens routing (undertrained) | 67.3% | +0.0pp |
| +Phase 3 | Self-verified repair | 74.6% | +7.3pp |
That pattern, generate multiple candidates, test them, debug the failures, iterate, is not exotic. It's how senior engineers work. ATLAS just automated it as an inference-time system.
The Cost Equation Enterprises Should Be Watching
Beyond raw scores, ATLAS surfaces a cost comparison that deserves attention. The project's README includes an honest cost-per-task breakdown:
| System | LiveCodeBench Score | Estimated Cost per Task |
|---|---|---|
| DeepSeek V3.2 Reasoning | 86.2% | ~$0.002 |
| GPT-5 (high) | 84.6% | ~$0.043 |
| ATLAS V3 | 74.6% | ~$0.004 |
| Claude 4.5 Sonnet | 71.4% | ~$0.066 |
ATLAS runs on electricity alone at roughly $0.12/kWh, processing 599 tasks in about two hours on a single GPU. No API keys, no usage metering, no data leaving the machine.

Now, this comparison has its own caveats. API costs are dropping steadily. Latency matters for production systems. And cloud models offer capabilities far beyond coding benchmarks, including general reasoning, multimodal understanding, and the kind of broad knowledge that a 14B parameter model simply doesn't match.
But for specific, well-defined workloads where you can build a verification pipeline around the output, the economics of orchestrated local inference are already competitive. And that gap will only close further as open-source models improve.
What This Actually Means for Enterprise AI Strategy
When people say AI progress is stagnating, they're typically watching a single metric: how much smarter is the newest base model compared to the last one? Those gains are slowing, and that's a legitimate observation. But it's also an incomplete picture.
ATLAS demonstrates that there's an entire dimension of improvement available through systems engineering alone. Not bigger models, not more training data, just smarter orchestration of the models we already have.
This has three direct implications for enterprise AI strategy.
The ceiling for your current models hasn't been reached. Most organizations deploy AI models as single-shot query engines. Ask a question, get an answer, move on. ATLAS proves that wrapping the same model in multi-candidate generation, automated verification, and self-repair loops can deliver dramatically better results. If you're disappointed with the output quality of your current AI deployments, the answer might not be a more expensive model. It might be a better system around the one you have.
Agentic pipelines are the next performance multiplier. The industry is already moving in this direction. Verification loops, multi-candidate generation, and self-repair mechanisms built on top of existing cloud models represent the next wave of improvements, and they don't require waiting for the next model release. Companies that invest in these orchestration patterns now will see compounding returns as the underlying models continue to improve.
The competitive moat is shifting. Access to frontier models is becoming commoditized. The APIs are available to everyone. Prices are dropping. The differentiator is increasingly not which model you have access to, but what you build around it. The organizations that develop sophisticated orchestration workflows, domain-specific verification systems, and intelligent routing mechanisms will outperform competitors running better base models with naive single-shot inference.
The Honest Limitations
A credible analysis requires acknowledging what ATLAS hasn't proven.
The system was designed and tuned specifically for LiveCodeBench. Its performance on other domains hasn't been optimized and the numbers reflect that. A general-purpose AI assistant needs to handle everything from creative writing to scientific reasoning to customer support. ATLAS in its current form is a coding pipeline, and a narrow one at that.
The verification phase (Phase 2) doesn't work yet. The Geometric Lens scoring mechanism was trained on only about 60 samples, far too few to learn meaningful patterns. The developer is transparent about this, which is refreshing, but it also means a key architectural component is essentially a placeholder.
Latency is a real tradeoff. A pipeline that takes minutes per task works for batch processing and asynchronous workflows. It doesn't work for the interactive, real-time use cases that drive most enterprise AI adoption today.
And the comparison with frontier models, while directionally interesting, isn't controlled. Same-benchmark, same-methodology evaluations would tell a much more precise story.
What I'm Watching Next
ATLAS V3.1 is already in development, with plans to swap the base model to a smaller but faster architecture, add task-level parallelization, and expand the benchmark suite beyond coding. If the self-repair mechanism generalizes across domains, that would be significant.
But the broader trend matters more than any single project. ATLAS is one example of a pattern that's emerging across the industry: inference-time compute scaling, agentic workflows, and systems-level optimization are delivering meaningful performance gains independent of base model improvements.

The next wave of AI ROI isn't only about GPT-6 or Claude Opus 5. It's about engineering smarter systems around the models that already exist.
AI hasn't stagnated. We've just been measuring progress on only one axis.